
The Page Indexing in Search Console shows the Google indexing status of all URLs that Google knows about in your property. In this latest blog post, I’m going to answer some common questions as well as show you how to fix ALL of these issues affecting your website. I’m also creating updated 2024 video lessons for troubleshooting common indexation issues.
First Ask Do You Need to Fix It?
If you are new to indexing or SEO, or have a small site, here’s what to consider before fixing these errors:
Decide whether you need to use this report in the first place. When a website is a small business website with fewer than 500 pages, you probably don’t need to use this report. Instead, use the following Google searches queries to see if important pages (or any pages) on your site are indexable. Examples:
- site:example.com
- site:example.com/petstore
If Google search does not show any result/s for your website, and you are willing to invest time to fully understand Page Indexing report to see why your website isn’t indexed. See the troubleshooting section of Page Indexing report. Having said that, here’s detailed yet practical how-tos.
Use URL Inspection Tool When Fixing Page Indexing Issues
Troubleshooting or even just identifying the actual cause of Page Indexing errors can be confusing for some website owners. The real dillemma doesn’t reside in fixing indexation issues, but rather, it is cumbersome identifying the cause since finding a solution often is simple. So, let’s first look at URL Inspection Tool Reports:
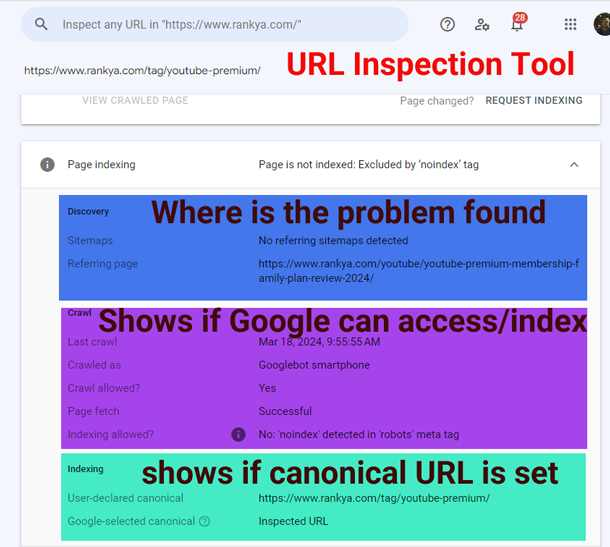 When Search Console Page Indexation reports shows an issue, this URL inspection tool is your friend, because in most cases, it will show you details about the problem you are trying to fix.
When Search Console Page Indexation reports shows an issue, this URL inspection tool is your friend, because in most cases, it will show you details about the problem you are trying to fix.

- Excluded by ‘noindex’ tag
- Page with redirect
- Not found (404)
- Duplicate without user-selected canonical
- Alternate page with proper canonical tag
- Blocked due to access forbidden (403)
- Soft 404
- Blocked by robots.txt
- Server error (5xx)
- Redirect error
- Crawled – currently not indexed (Google systems)
- Discovered – currently not indexed (Google systems)
- Duplicate, Google chose different canonical than user
- Indexed, though blocked by robots.txt
How-To Fix Page Indexing Issues
These problems for all Submitted URLs must be fixed for web pages to show up in Google search results. Let’s learn how to troubleshoot and find solution accordingly.
Excluded by ‘noindex’ tag
Excluded by ‘noindex’ tag report shows you, when Google tried to index the page, but when it tried, the web server or the website setting sent ‘noindex’ directive.
Video Lessons Explains What Excluded by ‘noindex’ tag Issues Are and How-To Fix It
Page with redirect
Page can not be indexed due to web page being redirected to another web page on your website. Basically, first identify the redirection using debugging tool such as Web Developer Toolbar (Network Tab Analysis) or Lighthouse may provide more details about the redirect issues. Common places to check:
- SSL (e.g. http not redirected to https)
- www or non-www isn’t redirecting properly
- website internal linking is still using incorrect URL pattern as submitted in XML Sitemaps
Video Lessons Explains What Page with redirect Issues Are and How-To Fix It
Not found (404)
Google gets this response because web server cannot find the requested resource. Although Page Not Found (404) responses are not necessarily a problem, if the web page has been deleted from your website. If your page has moved to another web page address, use 301 redirect to related content.
Also, since you are learning with RankYa, let me share a great insight with you. When checking the example URLs in Search Console you may see Referring Pages are coming from external websites to the 404 page. You need to visit the (referring as in backlinking web site) and ask “is the website based on quality according to Google guidelines?”. If so, using 301 redirection to related content on your own website will ensure your website doesn’t lose the back link relevance.
Video Lessons for Fixing Page Not found (404) Issues
Duplicate without user-selected canonical
When Google finds 2 or more URLs with the same (or near same) content, these pages can be seen as duplicate of another page. That is what Duplicate without user-selected canonical means. Best to fix such issues is using correct canonical URL or other methods of URL canonicalization, or else Google won’t serve the problem page in Search.
Video Tutorial for Duplicate without user-selected canonical
Alternate page with proper canonical tag
This is actually not a problem per se. Because Google has identified proper canonical URL since duplicate or alternate pages shouldn’t be indexed anyway. Having said this, the website owner needs to check and follow best practices when defining canonical URLs. Usually an issue on certain Content Management Systems, Multilingual sites or eCommerce sites. You can use robots.txt directives for pagination of URL, search results, archived URLs etc.).
Video Tutorial Showing Alternate page with proper canonical tag
Blocked due to access forbidden (403)
HTTP 403 means that the user agent provided credentials, but was not granted access. However, Googlebot never provides credentials, so your server is returning this error incorrectly. Basically means that Googlebot sees a URL that requires authentication credentials, and yet Googlebot never provides credentials.
Blocked due to access forbidden (403) is perfectly okay scenario for certain websites and there really is nothing to fix. For example: membership sites that require login credentials for private member only content. Or, eCommerce sites needing customers to login to their “account pages”. In such cases, the best thing you can do is use robots.txt file so that Google does NOT crawl the URL, and perhaps provide rel=’nofollow’ on URLs that require credentials (for example: for login url).
Video Tutorial Showing Blocked due to access forbidden (403)
Soft 404
A website sending Page Not Found 404 response codes are perfectly normal, almost all websites will naturally experience page not found 404 errors. Soft 404 on the other hand could be caused due to various reasons which may indicate more underlying issues that can drastically affect Google’s Page Fetch and Render process. Soft 404 provides bad user experience to visitors because it is telling them “page is here with 200 (success) Response Code, but then, display or suggest an error message or some kind of error on the page. Best way to test Live URL. Common places to check:
- A missing server-side include file.
- A broken connection to the database.
- An empty internal search result page.
- An unloaded or otherwise missing JavaScript file.
Blocked by robots.txt
Often occurs due to website using robots.txt file directives to URLs Google finds through other means. First thing to remember here is “do NOT use robots.txt file” to tell Google not to index certain URLs. If you do not want Google to not show certain URL in search results, then block indexing with noindex directive.
Blocked by robots.txt issue tells you that Google has found a URL on your website, tried to crawl it, but then robots.txt file blocked Google’s access for crawling. You can test using Google Search Console robots.txt tester to identify what is blocking Google, then, remove the blocking directive/s from robots.txt file on your web server.
Video Tutorial Showing Blocked by robots.txt
Server error (5xx)
One of the common errors seen in Google search console page indexing reports is the Server Errors. You can use Crawl Status reports to check (This report is available only for root-level properties).

NOTE: at times, although Googlebot may be able to crawl an URL, Googlebot may have issues during the Page Fetch and Render cycle. For example: web site theme requires internal CSS or javascript files to function properly, and yet, these files themselves may cause Internal Server Errors during Page Fetch or Render cycle.
Depending on content management system used, or programming language the website is built upon (PHP, asp, Javascript or others) you can debug website theme functionality. For example: for PHP built websites debug_backtrace to troubleshoot.
Video Tutorial Showing Server error (5xx)
Redirect error
 This report is related to Content Management System or Web Server as opposed to web page redirection. Common tools to use Web Developer Toolbar (press on F12 on your keyboard) to check Network status. You can also use Lighthouse on Chrome browser. Places to check on the web server:
This report is related to Content Management System or Web Server as opposed to web page redirection. Common tools to use Web Developer Toolbar (press on F12 on your keyboard) to check Network status. You can also use Lighthouse on Chrome browser. Places to check on the web server:
- error_logs
- Server Settings
- Server Redirection Settings
- PHP. JS ASP redirection settings
- SSL Settings
- domain redirection settings (e.g. www vs non-www)
NOTE: Page with redirect issues are different compared to Redirect errors (hence 2 distinct reports in Search Console Page Indexing Reports)
Video Tutorial Showing Redirect errors
Crawled – currently not indexed (Google systems)
Despite what Search Console help section may say about this particular issue. When Google crawls the URL (and is not blocked) it should index it.
But this report clearly shows that Google has not indexed the URL. Because one of the most misunderstood Page indexing issue is the problem/s due to Google Systems. This basically means that a web site or a particular web page doesn’t meet Google’s webmaster guideline requirements (as well as guidelines for any other Google product (e.g. Structured Data guidelines).
Video Tutorial Showing Crawled – currently not indexed (Google systems)
Discovered – currently not indexed (Google systems)
This issue is similar to the previous Crawled but not indexed issue. The only way to fix both of these types of issues are by following Google guidelines
Quick tip: you can update your current content on the web pages identified, add complimentary content (images, videos, PDFs etc.). If you’ve over optimized the landing page, then, reduce over SEOing URLs.
Or last option, analyze the URL results to see how its performing, then either block crawling using robots.txt, or remove the URL from your website and use 301 Redirection to related content.
Video Tutorial Showing Discovered – currently not indexed (Google systems)
Duplicate, Google chose different canonical than user
This issue means that the website is having issues with consolidating duplicate URLs.
Even if the URL has declared canonical URL, Google is ignoring user-declared canonical because Google Systems has identified better canonical version amongst all duplicate versions it has found on the website.
Usually an issue with Multilingual International Sites, eCommerce Sites, or pagination URLs. To fix it, ensure correct canonical URL is declared for duplicate version of the web page.
Indexed, though blocked by robots.txt
Google search indexing is a complex process. At basic level, Google may be blocked to crawl a URL using robots.txt, but that does NOT STOP Google indexing process. You have 2 options:
- Option 1 if you do NOT want the URL in Google index. Use noindex directive for the problem URL.
- Option 2 if you do WANT Google to index the URL, then, remove the robots.txt file directive that blocks Google crawl process.
Video Tutorial Showing Indexed, though blocked by robots.txt
Frequently Asked Questions
What Is Indexing?
- Indexing is the process by which search engines (such as Google) store and organize content found during their user-agent (Googlebot) crawling process.
- During crawling, search engines continually follow links (Uniform Resource Locator (URL)) to discover and collect data from web pages.
- The next step, indexing, involves organizing this collected content so that it can be easily retrieved when users search for specific keyword or word phrases.
- Easiest way to think about indexing is simply imagine a Microsoft Excel document row/column setting. Each Row will have a keyword and each Column will have URLs. That is to say "this keyword can be found on this URL".
- As far as Google search engine is concerned, its entire index consists of "keyword" index. These indexes also contain important information as to which URL (Uniform Resource Locator) the keyword/s are found on.
Hey please help me My website says page redirect when I test this link ‘omitted’ and the page indexing info says Google-selected canonical info: ‘omitted’ and the site is not appearing on google search
It is to do with your website WWW settings. Check your website internal links to ensure there are NO http://www.example.com links.
I Hosted my vite + react website on godaddy using cpanel and it is not showing up on google. my site name is ‘omitted’ someone please help me.
Your website is having more than Page with redirect issues. The reason Google is not indexing the web pages are because they are duplicates. Work on your content, fix links on the site: Legal Pages
Sitemap Website by in the footer, social buttons are BAD links. All of which will cause page indexing issues in Google search console.
Thank you very much for your article
You’re welcome Xia 🙂 since your business website is built on WordPress and you are using Yoast SEO plugin, you may want to search here https://www.rankya.com/?s=yoast also consider hiring one of the best website site optimizer on the planet ‘RankYa’
Can you give the exact answer why this website is not indexed on Google yet? It is more than 3 months.
You seemed to work as an SEO specialist, so should you not know why the website is still not indexed by Google? Without analyzing Search Console reports, we can’t tell you exactly why the page is not indexed by Google. But by briefly looking at your website, we can tell you to double check
Simply ask yourself, why would Google index your website when others in the same industry already are providing answers on a website that is optimized and provides original content and better user-experience. So here we are, you asked a simple question but there is not simple answer. Learn more about Page Indexing report here: https://support.google.com/webmasters/answer/7440203?hl=en