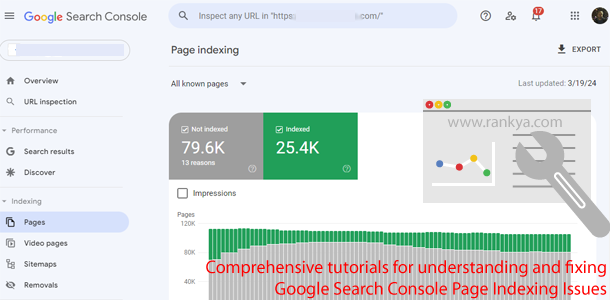
The Page Indexing in Search Console shows the Google indexing status of all URLs that Google knows about in your property. In this latest blog post, I’m going to answer some common questions as well as show you how to fix ALL of these issues affecting your website. I’m also creating updated 2024 video lessons… Continue reading Page Indexing
Tag: Page Indexing
How-To Fix Video Outside the Viewport
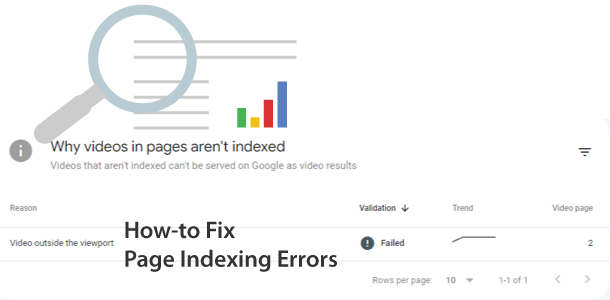
To troubleshoot video outside the Viewport errors as shown in Google Search Console Video Page Indexing reports. All you need to do is identify the video area on the page, and then move the video so that the entire video is inside the renderable area of the web page and seen when the page loads.… Continue reading How-To Fix Video Outside the Viewport
How to Fix Crawled Currently Not Indexed

Is your website encountering the “Crawled – currently not indexed” status in Google Search Console? This Page indexing status indicates that Googlebot (Google’s URL crawl bot) has visited a particular web page (for a verified website property in Search Console), but hasn’t yet added the web page to its index, which also means the web… Continue reading How to Fix Crawled Currently Not Indexed
How to Fix Blocked by robots.txt Errors

Search engines find information through crawling (which means they request / fetch a URL) to then analyze what they find on the URL. robots.txt rules should only be used to control the search engine crawling process but not indexing process. This means, most Search Console blocked by robots.txt errors arise due to incorrect rules used… Continue reading How to Fix Blocked by robots.txt Errors
How to Fix Excluded by noindex Tag

There are various methods a website URL can send NOINDEX directive telling search engines like Google to NOT index certain parts of a website. This is to block indexing of URLs. Fixing Excluded by ‘noindex’ tag Issues When troubleshooting Page indexing errors, do not waste time analyzing Page indexing reports for Excluded by ‘noindex’ tag… Continue reading How to Fix Excluded by noindex Tag
Page Indexing

New Google Search Console Page Indexing reports with Excluded and Error issues are now grouped into the status Not indexed. Google Search Console now shows you various issues a website may experience that can affect indexing of certain URLs. And because RankYa has been maintaining full course and how-to videos related to Google Search Console,… Continue reading Page Indexing